eLyXer Developer Guide
eLyXer Developer Guide
Alex Fernández (elyxer@gmail.com)
1 The Basics
This document should help you get started if you want to understand how eLyXer works, and maybe extending its functionality. The package (including this guide and all accompanying materials) is licensed under the
GPL version 3 or, at your option, any later version. See the
LICENSE file for details. Also visit the
main page to find out about the latest developments.
In this first section we will outline how eLyXer performs the basic tasks. Next section will be devoted to more arcane matters. The third section explains how to contribute to eLyXer, while the fourth one deals with future planned extensions. The fifth section includes things that will probably
not be implemented. Finally there is a FAQ that contains answers to questions asked privately and on the lyx-devel list
[7].
1.1 Getting eLyXer
If you are interested in eLyXer from a developer perspective the first thing to do is fetch the code. It is included in the standard distribution, so just navigate to the src/ folder and take a look at the .py Python code files.
For more serious use, or if your distribution did not carry the source code, or perhaps to get the latest copy of the code: you need to install the tool
git, created by Linus Torvalds (of Linux fame)
[8]. You will also need to have Python installed; versions at or above 2.4 should be fine
[9]. The code is hosted in Savannah
[1], a GNU project for hosting non-GNU projects. So first you have to fetch the code:
$ git clone git://git.sv.gnu.org/elyxer.git
You should see some output similar to this:
Initialized empty Git repository in /home/user/install/elyxer/.git/
remote: Counting objects: 528, done.
remote: Compressing objects: 100% (157/157), done.
remote: Total 528 (delta 371), reused 528 (delta 371)
Receiving objects: 100% (528/528), 150.00 KiB | 140 KiB/s, done.
Resolving deltas: 100% (371/371), done.
Now enter the directory that git has created.
$ cd elyxer
Your first task is to create the main executable file:
$ ./make
The build system for eLyXer will compile it for you, and even run some basic tests. (We will see later on section
3.1↓ how this “compilation” is done.) Now you can try it out:
$ cd docs/
$ ../elyxer.py devguide.lyx devguide2.html
You have just created your first eLyXer page! The result is in devguide2.html; to view it in Firefox:
$ firefox-bin devguide2.html
If you want to debug eLyXer then it is better to run it from the source code folder, instead of the compiled version. For this you need to make just a small change, instead of elyxer.py run src/principal.py:
$ ../src/principal.py --debug devguide.lyx devguide2.html
and you will see the internal debug messages.
Note for Windows developers: on Windows eLyXer needs to be invoked using the Python executable, and of course changing the slashes to backward-slashes:
> Python ..\elyxer.py devguide.lyx devguide2.html
or for the source code version:
> Python ..\src\elyxer.py devguide.lyx devguide2.html
If you want to install the created version you just have to run the provided install script as root:
# ./install
Once eLyXer has been installed it can be invoked as any other Unix command:
$ elyxer.py devguide.lyx devguide3.html
In the rest of this section we will delve a little bit into how eLyXer works.
1.2 Containers
The basic code artifact (or ‘class
↓’ in Python talk) is the
Container, located in the
gen package (file
src/gen/Container.py). Its responsibility is to take a bit of LyX code and generate working HTML code. This includes (with the aid of some helper classes): reading from file a few lines, converting it to HTML, and writing the lines back to a second file.
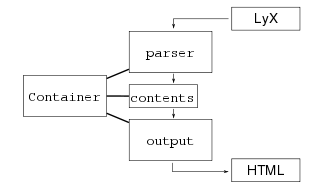
The following figure
1↓ shows how a
Container works. Each type of
Container should have a
parser and an
output, and a list of
contents. The
parser object receives LyX input and produces a list of
contents that is stored in the
Container. The
output object then converts those
contents to a portion of valid HTML code.
Two important class attributes of a Container are:
-
start: a string of text containing the LyX command that we are about to process;
-
and ending, which is used on some Containers to determine when to stop parsing.
A class called ContainerFactory has the responsibility of creating the appropriate containers, as the strings in their start attributes are found.
The basic method of a Container is:
-
process(): called after parsing the LyX text and before outputting the HTML result. Here the Container can alter its contents as needed, once everything has been read and before it is output.
Now we will see each subordinate class in detail.
1.3 Parsers
The package parse contains almost all parsing code; it has been isolated on purpose so that LyX format changes can be tackled just by changing the code in that directory.
A Parser has two main methods: parseheader() and parse().
parseheader(): parses the first line and returns the contents as a list of words. This method is common for all Parsers. For example, for the command ’\\emph on’ the Parser will return a list [’\\emph’,’on’]. This list will end up in the Container as an attribute header.
parse(): parses all the remaining lines of the command. They will end up in the Container as an attribute contents. This method depends on the particular Parser employed.
Basic Parsers reside in the file parser.py. Among them are the following usual classes:
LoneCommand: parses a single line containing a LyX command.
BoundedParser: reads until it finds the ending. For each line found within, the BoundedParser will call the ContainerFactory to recursively parse its contents. The parser then returns everything found inside as a list.
1.4 Outputs
Common outputs reside in output.py. They have just one method:
gethtml(): processes the contents of a Container and returns a list with file lines. Carriage returns \n must be added manually at the desired points; eLyXer will just merge all lines and write them to file.
Outputs do not however inherit from a common class; all you need is an object with a method gethtml(self,container) that processes the Container’s contents (as a list attribute). An output can also use all attributes of a Container to do their job.
1.5 Tutorial: Adding Your Own Container
If you want to add your own Container to the processing you do not need to modify all these files. You just need to create your own source file that includes the Container, the Parser and the output (or reuse existing ones). Once it is added to the types in the ContainerFactory eLyXer will happily start matching it against LyX commands as they are parsed.
There are good examples of parsing commands in just one file in
image.py and
formula.py. But let us build our own container
BibitemInset here. We want to parse the LyX command in listing
1↓. In the resulting HTML we will generate an anchor: a single tag
<a name="mykey"> with fixed text
"[ref]".
\begin_inset CommandInset bibitem
LatexCommand bibitem
key "mykey"
\end_inset
Algorithm 1 The LyX command to parse.
We will call the
Container BibitemInset, and it will process precisely the inset that we have here. We will place the class in
bibitem.py. So this file starts as shown in listing
2↓.
class BibitemInset(Container):
"An inset containing a bibitem command"
start = ’\\begin_inset CommandInset bibitem’
ending = ’\\end_inset’
Algorithm 2 Class definition for BibitemInset.
We can use the parser for a bounded command with start and ending,
BoundedParser. For the output we will generate a single HTML tag
<a>, so the
TagOutput() is appropriate. Finally we will set the
breaklines attribute to
False, so that the output shows the tag in the same line as the contents:
<a …>[ref]</a>. Listing
3↓ shows the constructor.
def __init__(self):
self.parser = BoundedParser()
self.output = TagOutput()
self.tag = ’a’
self.breaklines = False
Algorithm 3 Constructor for BibitemInset.
The
BoundedParser will automatically parse the header and the contents. In the
process() method we will discard the first line with the
LatexCommand, and place the key from the second line as link destination. The class
StringContainer holds string constants; in our case we will have to isolate the key by splitting the string around the double quote
", and then access the anchor with the same name. The contents will be set to the fixed string
[ref]. The result is shown in listing
4↓.
def process(self):
#skip first line
del self.contents[0]
# parse second line: fixed string
string = self.contents[0]
# split around the "
key = string.contents[0].split(’"’)[1]
# make tag and contents
self.tag = ’a name="’ + key + ’"’
string.contents[0] = ’[ref] ’
Algorithm 4 Processing for BibitemInset.
And then we have to add the new class to the types parsed by the
ContainerFactory; this has to be done outside the class definition. The complete file is shown in listing
5↓.
from parser import *
from output import *
from container import *
class BibitemInset(Container):
"An inset containing a bibitem command"
start = ’\\begin_inset CommandInset bibitem’
ending = ’\\end_inset’
def __init__(self):
self.parser = BoundedParser()
self.output = TagOutput()
self.breaklines = False
def process(self):
#skip first line
del self.contents[0]
# parse second line: fixed string
string = self.contents[0]
# split around the "
key = string.contents[0].split(’"’)[1]
# make tag and contents
self.tag = ’a name="’ + key + ’"’
string.contents[0] = ’[ref] ’
ContainerFactory.types.append(BibitemInset)
Algorithm 5 Full listing for BibitemInset.
The end result of processing the command in listing
1↑ is a valid anchor:
<a name="mykey">[ref] </a>
The final touch is to make sure that the class is run, importing it in the file
gen/factory.py, as shown in listing
6↓. This ensures that the
ContainerFactory will know what to do when it finds an element that corresponds to the
BibitemInset.
…
from structure import *
from bibitem import *
from container import *
…
Algorithm 6 Importing the BibitemInset from the factory file.
Now this Container is not too refined: the link text is fixed, and we need to do additional processing on the bibitem entry to show consecutive numbers. The approach is not very flexible either: e.g. anchor text is fixed. But in less than 20 lines we have parsed a new LyX command and have outputted valid, working XHTML code. The actual code is a bit different but follows the same principles; it can be found in src/bib/biblio.py: in the classes BiblioCite and BiblioEntry, and it processes bibliography entries and citations (with all our missing bits) in about 50 lines.
2 Advanced Features
This section tackles other, more complex features; all of them are included in current versions.
2.1 Parse Tree
On initialization of the ContainerFactory, a ParseTree is created to quickly pass each incoming LyX command to the appropriate containers, which are created on demand. For example, when the ContainerFactory finds a command:
\\emph on
it will create and initialize an EmphaticText object. The ParseTree works with words: it creates a tree where each keyword has its own node. At that node there may be a leaf, which is a Container class, and/or additional branches that point to other nodes. If the tree finds a Container leaf at the last node then it has found the right point; otherwise it must backtrack to the last node with a Container leaf.
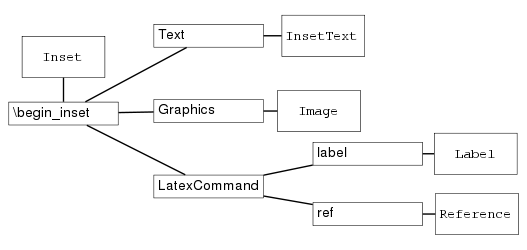
Figure
2↓ shows a piece of the actual parse tree. You can see how if the string to parse is
\begin_inset LatexCommand, at the node for the second keyword
LatexCommand there is no leaf, just two more branches
label and
ref. In this case the
ParseTree would backtrack to
begin_inset, and choose the generic
Inset.
Parsing is much faster this way, but there are disadvantages; for one, parsing can only be done using whole words and not prefixes. SGML tags (such as <lyxtabular>) pose particular problems: sometimes they may appear with attributes (as in <lyxtabular version="3">), and in this case the starting word is <lyxtabular without the trailing ’>’ character. So the parse tree removes any trailing ’>’, and the start string would be just <lyxtabular; this way both starting words <lyxtabular> and <lyxtabular are recognized.
2.2 Postprocessors
Some post-processing of the resulting HTML page can make the results look much better. The main stage in the postprocessing pipeline inserts a title “Bibliography” before the first bibliographical entry. But more can be added to alter the result. As eLyXer parses a LyX document it automatically numbers all chapters and sections. This is also done in the postprocessor.
The package post contains most postprocessing code, although some postprocessors are located in the classes of their containers for easy access.
2.3 Mathematical Formulae
Formulae in LyX are rendered beautifully into TeX and PDF documents. For HTML the conversion is not so simple. There are basically three options:
-
render the formula as an image (GIF or PNG), then import the image;
-
export a specific language called MathML
-
or render using a variety of Unicode characters, HTML and CSS wizardry [2].
eLyXer employs the third technique, with varied results. Basic fractions and square roots should be rendered fine, albeit at the moment there may be some issues pending. Complex fractions with several levels do not come out right. (But see subsection
2.4↓.)
2.4 MathML
There are two options in place to generate MathML, as suggested by Günther Milne and Abdelrazak Younes
[4, 5]. Both rely on some JavaScript page manipulations, and they need to be hosted on the same server as the documents. MathJax is less mature but it has grown faster so it has become the preferred option.
To use this last option in your own pages you just have to add the --mathjax option:
$ elyxer.py --mathjax ./MathJax math.lyx math.html
You will notice that the
--mathjax option requires an argument: the directory where MathJax resides. MathJax needs to live on your server; after
downloading the package, deploy it to your server and give the installation directory as an argument to
--mathjax.
In principle you might think of using some external installation of MathJax to avoid downloading it and serving it from your server, e.g. from Savannah:
$ elyxer.py --mathjax http://elyxer.nongnu.org/MathJax/ math.lyx math.html
This approach may not work on certain browsers for two reasons: JavaScript loaded from a different site may not work, and WebFonts are also subject to this same-origin policy. If you have made it work it would be great to hear about it.
2.5 Baskets
eLyXer supports a few distinct modes of operation. In each incarnation the tasks to do are quite different:
-
A pure filter↓: read from disk and write to disk each Container, keeping no context in memory.
-
In-memory processing: read a complete file, process it and write it all to disk.
-
TOC↓ generation: output just a table of contents for a LyX document.
-
Split document generation: separates each chapter, section or subsection in a different file.
How can it do so many different tasks without changing a lot of code? The answer is in the file gen/basket.py. A Basket is an object that keeps Containers. Once a batch is ready, the Basket outputs them to disk or to some other Basket, but it may decide to just wait a little longer.
The basic Basket is the WriterBasket: it writes everything that it gets to disk immediately and then forgets about it. Some bits of state are kept around, like for example which biliography entries have been found so far, but the bulk of the memory is released.
Another more complex object is the TOCBasket: it checks if the Container is worthy to appear in a TOC, and otherwise just discards it. For chapters, sections and so on it converts them to TOC entries and outputs them to disk.
The MemoryBasket does most of its work in memory: it stores all Containers until they have all been read, then does some further processing on them and outputs an improved version of the document, at the cost of using quite more memory. This allows us for example to generate a list of figures or to set consecutive labels for bibliography entries (instead of just numbering them as they appear in the text).
The most complex kind of Basket is the SplittingBasket: it writes each document part to a separate file, choosing what parts to split depending on the configuration passed in the --splitpart option. By default it creates a TOC at the top of each page.
2.6 Hybrid Functions
Math processing is very configurable; most of it is based on configuration options found in src/conf/base.cfg. Parsing can be done using a few simple functions: commands (contained in [FormulaConfig.commands]) output some content and don’t have any parameters, while one-parameter functions (in [FormulaConfig.onefunctions]) take exactly one parameter and output an HTML tag. Thus, the definition for \bar is:
Whenever eLyXer finds the command it parses a parameter, then outputs the tag <span class="bar"> surrounding the parameter. For instance: e.g. \bar{38} becomes <span class="bar">38</span> in the output. Decorating functions (in [FormulaConfig.decoratingfunctions]) place a symbol from in the definition above the parameter, and so on.
Such simple processing is not always enough; there is a generic mechanism for producing complex output from a number of parameters. They are called hybrid functions.
Each definition for a hybrid function contains: parser definition, output definition and a number of function tags. The parser definition tells eLyXer what to parse. Hybrid functions can have any number of optional parameters, denoted as [$p]; mandatory parameters are shown as {$p}. Each parameter consists of the symbol $ followed by a letter or number: $0, $p.
The output definition contains regular text, plus parameters and functions. Each function consists of the letter f plus a number, such as f0; and each is associated with a tagged HTML element. These function tags are the last part of the definition. Presently there can be as many as 10 function tags (from f0 to f9).
Let us see a simple example, equivalent to the above formula — a one-parameter, one-tag hybrid function:
\fun:[{$p},f0{$p},span class="fun"]
The only function tag f0 generates the HTML tag <span class="fun">. Whenever eLyXer finds \fun in a math formula, it will parse one parameter and put it into $p. Then it will generate f0{$p}, i.e. apply the tag <span class="fun">. Putting it all together: \fun{38} becomes <span class="fun">38</span>.
Parameters can be parsed as a literal, in which case eLyXer will take everything between the brackets without parsing it. Literal parameters can be used within a tag definition. A real life hybrid function with literal parameters:
\raisebox:[{$p!}{$1},f0{$1},span class="raisebox" style="vertical-align: $p;"]
In this case there are two mandatory parameters, the first one literal and the second one a regular TeX expression. The output is just one function tag, in this case using the first mandatory parameter. For instance, \raisebox{3cm}{5} would generate:
<span class="raisebox" style="vertical-align: 3cm;">5</span>
The parameter $p is parsed as 3cm, which is not parsed further.
Hybrid functions are easy to configure once you get the hang of it. Adding new TeX commands, even complex ones, becomes simply a matter of configuration.
3 Developing and Contributing
This chapter will show you how to further develop eLyXer and how to contribute your own code.
3.1 Distribution
You will notice that in the src/ folder there are several Python files, while in the main directory there is just a big one called elyxer.py. The reason is that before distributing the source code is coalesced and placed on the main directory, so that users can run it without worrying about libraries, directories and the such. (They need of course to have Python 2.5 installed.) And the weapon is a little Python script called coalesce.py that does the dirty job of parsing dependencies and inserting them into the main file. There is also a make Bash script that takes care of permissions and generates the documentation. Just type
$ ./make
at the prompt. This coalesces all code and configuration into elyxer.py. It is a primitive way perhaps to generate the “binary” (ok, not really a binary but a distributable Python file), but it works great.
The make script also runs all of the included tests to check that no functionality has been lost from one release to the next. These tests can also be run independently using the run-tests script:
$ ./run-tests
They are used to verify that no functionality is lost from one version to the next — although issues can certainly slip undetected if there is no test for them.
At the moment there is no way to do this packaging on non-Unix operating systems with a single script, e.g. a Windows .bat script. However the steps themselves are trivial.
3.2 Debugging
Code problems are quite difficult to debug using the full elyxer.py file. It is much better to use the uncoalesced version instead, since it is quite modular and neatly divided. To do so you just need to locate the file src/principal.py and run that instead of elyxer.py. For example, if you are in the docs/ directory and you want to convert math.lyx you can run eLyXer as:
$ ../src/principal.py math.lyx math.html
For extra debugging information you can activate the --debug option:
$ ../src/principal.py --debug math.lyx math.html
This will make any traces more meaningful and will let you follow the code much more easily.
3.3 Configuration
The make script does not just construct a single .py file from all sources; it is also used to extract the configuration in human-readable form and create a Python file which is then coalesced with all the rest. The original configuration file (the one you should modify) is called base.cfg, while the resulting Python file is called config.py.
The original configuration file uses this format:
[ContainerConfig.startendings]
\begin_deeper:\end_deeper
\begin_inset:\end_inset
\begin_layout:\end_layout
where each section header is enclosed in square brackets; it contains an object name and a section name. In the example above the object is called ContainerConfig, while the section is called startendings. Inside each section there are a number of key:value pairs separated by a colon; the key is used to reference the value in other Python code.
To create config.py go to the src/ folder and type:
$ ./exportconfig py
This will create all configuration objects to be used inside your Python code, where each section will become an object attribute containing a map. For instance, to access the first value above \end_deeper you would write in your Python code:
ContainerConfig.startendings[’\begin_deeper’]
Each section can contain as many values as needed.
3.4 License
eLyXer is published under the GPL, version 3 or later
[3]. This basically means that you can modify the code and distribute the result as desired, as long as you publish your modifications under the same license. But consult a lawyer if you want an authoritative opinion.
3.5 Contributions
All contributions will be published under this same license, so if you send them this way you implicitly give your consent. An explicit license grant would be even better and may be required for larger contributions.
Please send any suggestions, patches, ideas and whatever else related to development to the
mailing list. (Alternatively you may contact
elyxer@gmail.com privately.) If you are willing to create a patch and submit it, you should patch against the proper sources in
src/ and send it to the list. This will make everyone’s lives better than if you patch against
elyxer.py.
The first external patches have started arriving during late 2009 and early 2010 (provided by Olivier Ripoll, Geremy Condra and Simon South). You can join in the fun!
4 Roadmap
You can see what user features are planned for the near feature in the
wish list.
After the release of eLyXer 1.0, the goal is full LyX document support; any deviation from the output of LyX on e.g. PDF will be considered as bugs. (Keep in mind that some deviations arise in an inherent limitation in the design of eLyXer, and these will logically not be considered as bugs.)
For eLyXer 1.3.0 there are plans to convert it into a proper Python package so it can be installed using full source code (and not a coalesced script elyxer.py that contains everything). Also, once ERTs are parsed, eLyXer might be extended for 1.3.0 to translate generic LaTeX documents.
All this within the usual constraints: day job, family, etc.
5 Discarded Bits
Some features suggested for eLyXer have been discarded; they do not fit with the design of eLyXer or are too much effort for the proposed gains.
5.1 Spellchecking
LyX can use a spellchecker to verify the words used. However it is not interactive so you may forget to run it before generating a version. It is possible to integrate eLyXer with a spellchecker and verify the spelling before generating the HTML, but it is not clear that it can be done cleanly.
5.2 URL Checking
Another fun possibility is to make eLyXer check all the external URLs embedded in the document. However the Python facilities for URL checking are not very mature, at least with Python 2.5: some of them do not return errors, others throw complex exceptions that have to be parsed… It is far easier to just create the HTML page and use wget (or a similar tool) to recursively check all links in the page.
5.3 Use of lyx2lyx Framework
Abdelrazak Younes suggests using the
lyx2lyx framework, which after all already knows about LyX formats
[5]. It is an interesting suggestion, but one that for now does not fit well with the design of eLyXer: a standalone tool to convert between two formats, or as Kernighan and Plauger put it, a standalone
filter [6]. Long-term maintenance might result a bit heavier with this approach though, especially if LyX changes to a different file format in the future.
6 FAQ
Q: I don’t like how your tool outputs my document, what can I do?
A: First make sure that you are using the proper CSS file, i.e. copy the existing docs/lyx.css file to your web page directory. Next try to customize the CSS file to your liking; it is a flexible approach that requires no code changes. Then try changing the code (and submitting the patch back).
Q: How is the code maintained?
A: It is kept in a
git repository
on Savannah. Patches in
git format are welcome (but keep in mind that my knowledge of
git is even shallower than my Python skills).
Q: I found a bug, what should I do?
Nomenclature
↑class A self-contained piece of code that hosts attributes (values) and methods (functions).
↑filter A type of program that reads from a file and writes to another file, keeping in memory only what is needed short term.
References
[1] Free Software Foundation, Inc.: eLyXer summary. https://savannah.nongnu.org/projects/elyxer/
[2] S White: “Math in HTML with CSS”, accessed March 2009. http://www.zipcon.net/~swhite/docs/math/math.html
[3] R S Stallman et al: “GNU GENERAL PUBLIC LICENSE” version 3, 20070629. http://www.gnu.org/copyleft/gpl.html
[4] G Milde: “Re: eLyXer: LyX to HTML converter”, message to list lyx-devel, 20090309. http://www.mail-archive.com/lyx-devel@lists.lyx.org/msg148627.html
[5] A Younes: “Re: eLyXer: LyX to HTML converter”, message to list lyx-devel, 20090309. http://www.mail-archive.com/lyx-devel@lists.lyx.org/msg148634.html
[6] B W Kernighan, P J Plauger: “Software Tools”, ed. Addison-Wesley Professional 1976, p. 35.
[7] Various authors: “lyx-devel mailing list”, accessed November 2009. http://www.mail-archive.com/lyx-devel@lists.lyx.org/
[8] S Chacon: “Git — Download”, accessed November 2009. http://git-scm.com/download
[9] Python community: “Download Python”, accessed November 2009. http://www.python.org/download/